두괄식으로 말하자면 : 안 고쳐졌다. 못 쓴다.
제어판 > 시계 및 국가 > 국가 또는 지역 > 날짜, 시간 또는 숫자 형식 변경 > 관리자 옵션에서...
시스템 로캘 변경이라는 버튼이 있고 이 버튼을 누르면 베타 기능인 '세계 언어 지원을 위해 Unicode UTF-8 사용이 있다.

저걸 켜면 윈도우 터미널에서 텍스트 입력을 할 때도 UTF-8을 사용할 수 있다고 해서 켜봤다.
C언어에서 한글 UTF-8로 받아보려고.
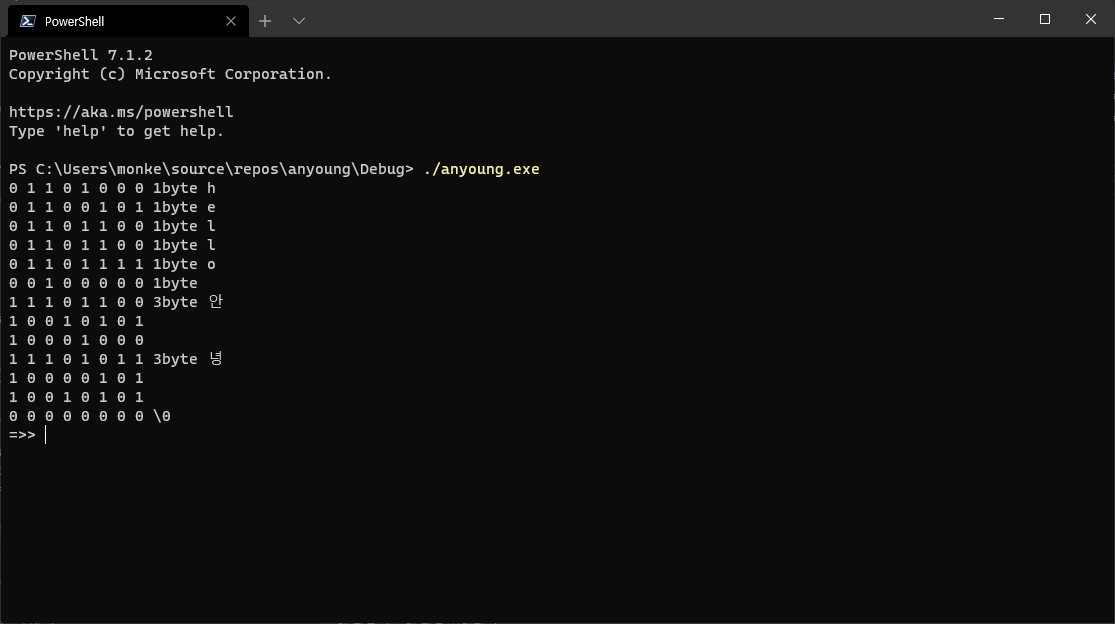
내가 만든 프로그램이다.
char 배열로 된 문자열을 가지고 한 글자씩. 그리고 utf-8에서는 몇 바이트인지 알 수 있을테니까 그걸로 값 출력하고.
기본값으로 "hello 안녕" 을 넣어놨는데 잘 출력되는 모습이다.
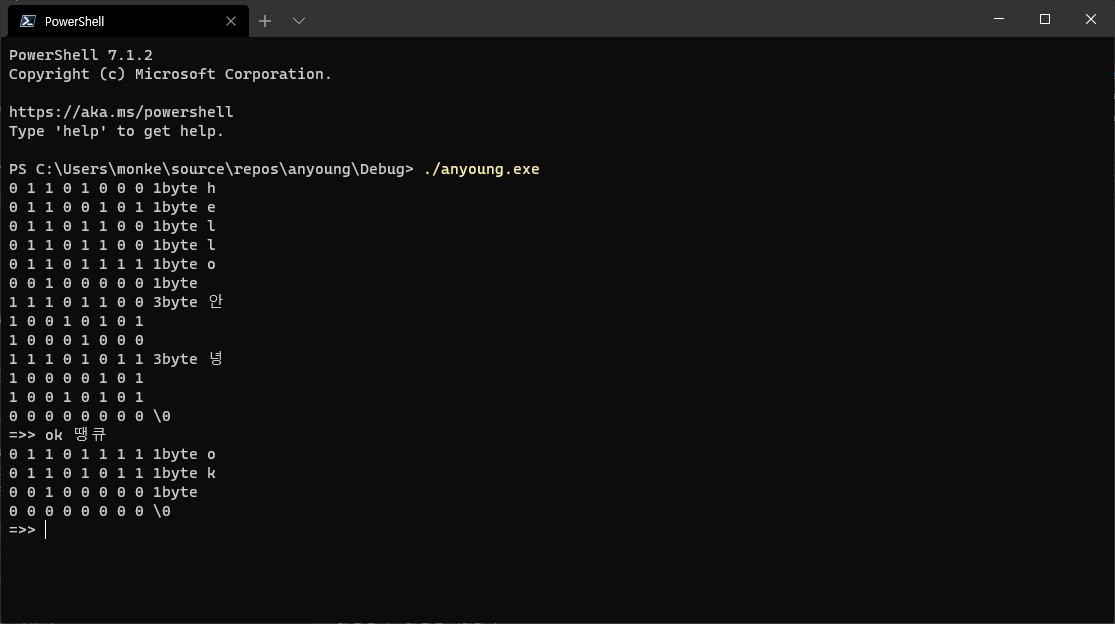
"ok 땡큐" 를 입력해본 결과...
o와 k와 스페이스바 까지만 "땡" 글자의 첫 바이트가 있어야될 부분이 0으로 바뀌어있었다.
\0이나 \n을 찾으면 반복을 멈추게 만들어 놔서 반복이 멈췄고.
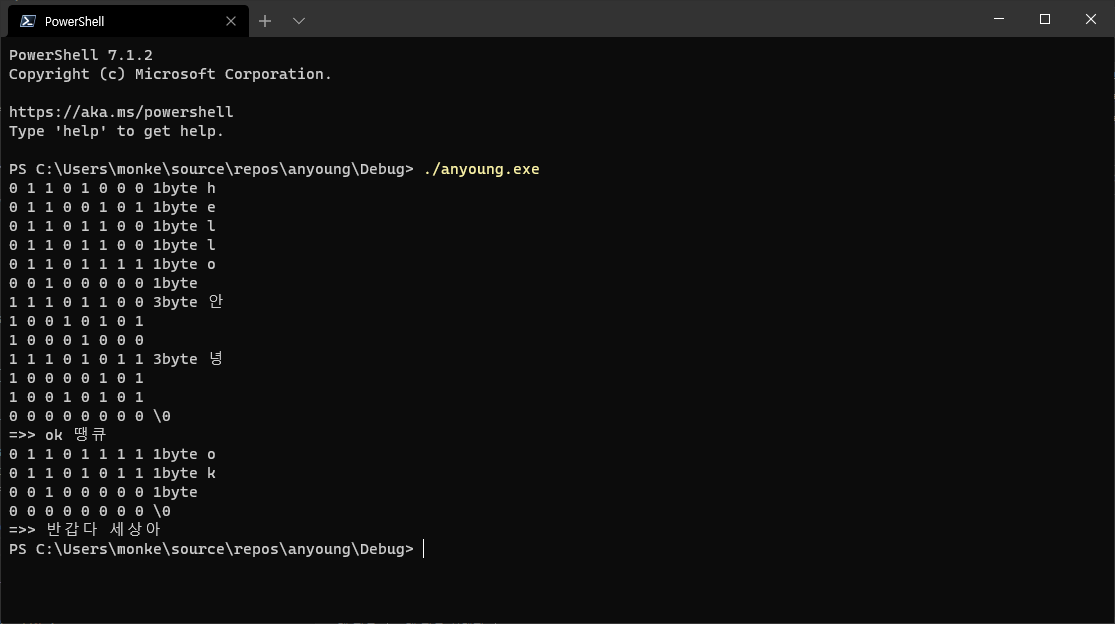
첫 글자가 한글인 텍스트를 입력하면 시작도 하지 않는다.
마찬가지로 첫 글자가 \0이나 \n이면 프로그램을 종료하게 만들어 놔서 그렇긴 하다.
어쨌든 무슨 이유에서인지 한글이 0으로 대체되었다.

리눅스 기반 온라인 컴파일러다. 여기서는 잘 된다. 리눅스에서도 아마 잘 될 것이다.
그런데 내가 이걸 리눅스에서 돌리자고 만든게 아니지 않나? 무슨 문제인지 검색해봤다.
https://github.com/dotnet/runtime/issues/43295
Console UTF-8 input is misbehaving on Windows · Issue #43295 · dotnet/runtime
Description using System; namespace Test { static class Program { static void Main() { Console.WriteLine(Console.InputEncoding); Console.WriteLine(Console.OutputEncoding); Console.WriteLine(); Cons...
github.com
https://github.com/microsoft/terminal/issues/4551
COOKED_READ doesn't return UTF-8 on *A APIs in CP_UTF8 · Issue #4551 · microsoft/terminal
Environment Microsoft Windows [Version 10.0.18363.592] Impact This issue is affecting reading console input via the Universal C Runtime as well - _read, getchar, fread, scanf, etc. Using _cgets_s o...
github.com
그럴듯한 내용이 두 개 나왔는데 하나는 닷넷 쪽이고 하나는 윈도우 터미널 쪽이다.
닷넷쪽에선 내용이 닷넷 코어 프로젝트에서만
abcæøådef를 입력하면
abc def가 출력된다는 것이다.
대답은 위에 유니코드 설정 되물어보기와 레지스트리 값 확인 정도였다.
닷넷 프레임워크에서도 비슷한 사례가 나타났다고 하는 댓글도 있다.
두어개의 다른 질문들이 여기로 병합된 걸로 봐서 비슷한 일이 꽤 있었나 보다.
윈도우 쪽에서는 C언어에서 한자를 입력하는 상황을 예로 들고 있다.
닷넷보다 설명이 부실하고 코드 복붙이 심하긴 한데 어쨌든 같은 상황인 것 같다.
여기에는 어떤 사용자가 장문의 댓글을 달았다.
|
ReadFile and are currently limited to 7-bit ASCII when the input codepage is UTF-8 (65001) due to an assumption of 1 per when calling .ReadConsoleACHARWCHARWideCharToMultiByte A ordinal in the range [0x000000, 0x00FFFF], i.e. the Basic Multilingual Plane (BMP), uses a single value. UTF-8 uses 1 byte per ASCII ordinal in the range [0x000000, 0x00007F]. UTF-8 uses 2-3 bytes per non-ASCII ordinal in the range [0x000080, 0x00FFFF]. A non-BMP ordinal in the range [0x010000, 0x10FFFF] uses two values to store a UTF-16 surrogate pair. UTF-8 uses 4 bytes per non-BMP ordinal. (The maximum Unicode ordinal is capped by design at 0x10FFFF for compatibility with UTF-16, which uses a reserved 10-bit range in a pair of 16-bit codes to support a 20-bit space with an additional 16 supplementary planes, e.g. [0x010000, 0x01FFFF], [0x020000, 0x02FFFF], and so on up to [0x100000, 0x10FFFF].)WCHARWCHAR For non-ASCII ordinals, the internal call fails, and the initial null byte value is used. In Windows 10, with the new console enabled, we get 1 null byte in the result per because it encodes one code at a time. For non-BMP ordinals, given the assumption of one per and encoding one code at a time (i.e. naive handling of surrogate pairs), we should get two null bytes per non-BMP ordinal. However, with the new console I can't even get wide-character to work with non-BMP ordinals. It translates a UTF-16 surrogate pair to the replacement character (0x00FFFD). works fine with non-BMP ordinals in the legacy console, so some change in the new console has broken UTF-16 support in cooked reads.WideCharToMultiByteWCHARCHARWCHARReadConsoleWReadConsoleW For and in older versions of Windows, or if we enable the legacy console in Windows 10, using UTF-8 as the input codepage causes a 'successful' read of 0 bytes if the read contains even one non-ASCII ordinal. Many programs interpret a successful read of 0 bytes as EOF.ReadFileReadConsoleA |
대강 Ascii 값 영어랑 숫자 정도만 사용할 수 있다는 뜻이다.
그리고 윈도우는 기본적으로 utf-16을 써왔고, wchar 자료형이 있고, 유니코드가 너무 많아지고...
어쨌든 둘 다 github에서는 open issue고 아직 안 고쳐졌다.
마이크로소프트에서 고쳐줄 때까지 기다려야지.
+ 사용한 c언어 프로그램은...
#include <stdio.h>
void printBit(unsigned char a)
{
printf("%d %d %d %d %d %d %d %d",
(a >> 7) % 2,
(a >> 6) % 2,
(a >> 5) % 2,
(a >> 4) % 2,
(a >> 3) % 2,
(a >> 2) % 2,
(a >> 1) % 2,
(a >> 0) % 2);
}
int main()
{
char chars[80] = "hello 안녕";
unsigned char a;
int i = 0;
int j = 0;
while (chars[0] != '\n' && chars[0] != '\0')
{
for (i = 0; i < sizeof(chars) / sizeof(char); j++)
{
a = chars[i];
printBit(a);
if (a == '\n')
{
printf(" \\n");
break;
}
else if (a == '\0')
{
printf(" \\0");
break;
}
else if ((a >> 7) % 2 == 0)
{
printf(" 1byte %c", chars[i]);
}
else if (
((a >> 7) % 2 == 1)
&& ((a >> 6) % 2 == 1)
&& ((a >> 5) % 2 == 0))
{
printf(" 2byte %c%c", chars[i], chars[i + 1]);
}
else if (
((a >> 7) % 2 == 1)
&& ((a >> 6) % 2 == 1)
&& ((a >> 5) % 2 == 1)
&& ((a >> 4) % 2 == 0))
{
printf(" 3byte %c%c%c", chars[i], chars[i + 1], chars[i + 2]);
}
else if (
((a >> 7) % 2 == 1)
&& ((a >> 6) % 2 == 1)
&& ((a >> 5) % 2 == 1)
&& ((a >> 4) % 2 == 1)
&& ((a >> 3) % 2 == 0))
{
printf(" 4byte %c%c%c%c", chars[i], chars[i + 1], chars[i + 2], chars[i + 3]);
}
i += 1;
printf("\n");
}
printf("\n=>> ");
fgets(chars, 80, stdin);
}
return 0;
}